What is the Softmax Function?
The softmax function is a function that turns a vector of K real values into a vector of K real values that sum to 1. The input values can be positive, negative, zero, or greater than one, but the softmax transforms them into values between 0 and 1, so that they can be interpreted as probabilities. If one of the inputs is small or negative, the softmax turns it into a small probability, and if an input is large, then it turns it into a large probability, but it will always remain between 0 and 1.
The softmax function is sometimes called the softargmax function, or multi-class logistic regression. This is because the softmax is a generalization of logistic regression that can be used for multi-class classification, and its formula is very similar to the sigmoid function which is used for logistic regression. The softmax function can be used in a classifier only when the classes are mutually exclusive.
Many multi-layer neural networks end in a penultimate layer which outputs real-valued scores that are not conveniently scaled and which may be difficult to work with. Here the softmax is very useful because it converts the scores to a normalized probability distribution, which can be displayed to a user or used as input to other systems. For this reason it is usual to append a softmax function as the final layer of the neural network.
Softmax Formula
The softmax formula is as follows:
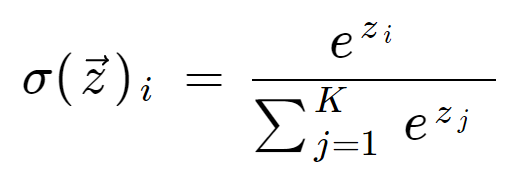
Mathematical definition of the softmax function
where all the zi values are the elements of the input vector and can take any real value. The term on the bottom of the formula is the normalization term which ensures that all the output values of the function will sum to 1, thus constituting a valid probability distribution.
Softmax Formula Symbols Explained
| The input vector to the softmax function, made up of (z0, ... zK) | |
| All the zi values are the elements of the input vector to the softmax function, and they can take any real value, positive, zero or negative. For example a neural network could have output a vector such as (-0.62, 8.12, 2.53), which is not a valid probability distribution, hence why the softmax would be necessary. | |
 |
The standard exponential function is applied to each element of the input vector. This gives a positive value above 0, which will be very small if the input was negative, and very large if the input was large. However, it is still not fixed in the range (0, 1) which is what is required of a probability. |
 |
The term on the bottom of the formula is the normalization term. It ensures that all the output values of the function will sum to 1 and each be in the range (0, 1), thus constituting a valid probability distribution. |
| The number of classes in the multi-class classifier. |
Calculating the Softmax
Imagine we have an array of three real values. These values could typically be the output of a machine learning model such as a neural network. We want to convert the values into a probability distribution.

First we can calculate the exponential of each element of the input array. This is the term in the top half of the softmax equation.
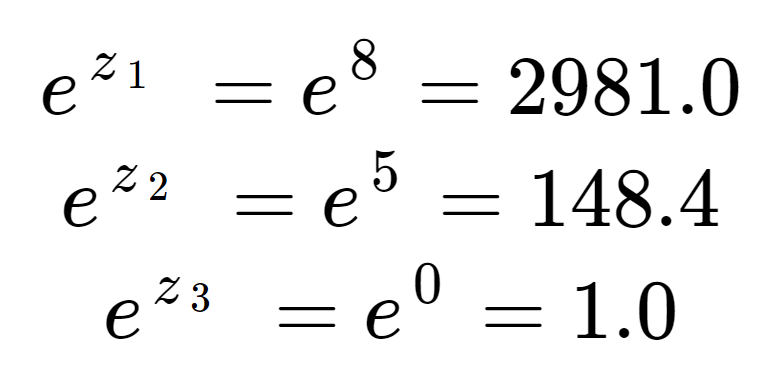
These values do not look like probabilities yet. Note that in the input elements, although 8 is only a little larger than 5, 2981 is much larger than 148 due to the effect of the exponential. We can obtain the normalization term, the bottom half of the softmax equation, by summing all three exponential terms:

We see that the normalization term has been dominated by z1.
Finally, dividing by the normalization term, we obtain the softmax output for each of the three elements. Note that there is not a single output value because the softmax transforms an array to an array of the same length, in this case 3.
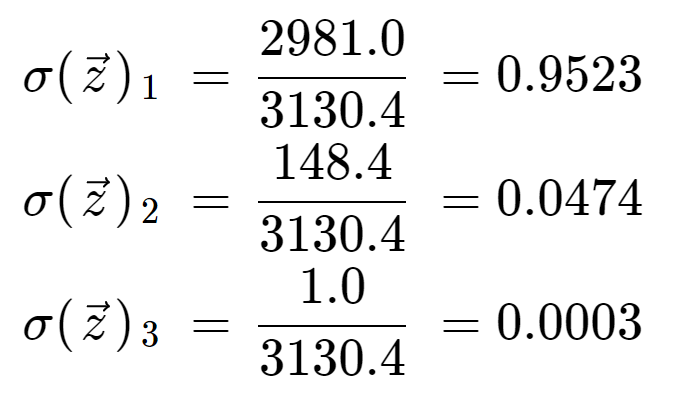
It is informative to check that we have three output values which are all valid probabilities, that is they lie between 0 and 1, and they sum to 1.
Note also that due to the exponential operation, the first element, the 8, has dominated the softmax function and has squeezed out the 5 and 0 into very low probability values.
If you use the softmax function in a machine learning model, you should be careful before interpreting it as a true probability, since it has a tendency to produce values very close to 0 or 1. If a neural network had output scores of [8, 5, 0], like in this example, then the softmax function would have assigned 95% probability to the first class, when in reality there could have been more uncertainty in the neural network’s predictions. This could give the impression that the neural network prediction had a high confidence when that was not the case.
Softmax Function vs Sigmoid Function
As mentioned above, the softmax function and the sigmoid function are similar. The softmax operates on a vector while the sigmoid takes a scalar.

In fact, the sigmoid function is a special case of the softmax function for a classifier with only two input classes. We can show this if we set the input vector to be [x, 0] and calculate the first output element with the usual softmax formula:

Dividing the top and bottom by ex, we get:

This shows that the sigmoid function becomes equivalent to the softmax function when we have two classes. It is not necessary to calculate the second vector component explicitly because when there are two probabilities, they must sum to 1. So, if we are developing a two-class classifier with logistic regression, we can use the sigmoid function and do not need to work with vectors. But if we have more than two mutually exclusive classes the softmax should be used.
If there are more than two classes and they are not mutually exclusive (a multi-label classifier), then the classifier can be split into multiple binary classifiers, each using its own sigmoid function.
Calculating Softmax Function vs Sigmoid Function
If we take an input vector [3, 0], we can put this into both the softmax and sigmoid functions. Since the sigmoid takes a scalar value we put only the first element into the sigmoid function.

The sigmoid function gives the same value as the softmax for the first element, provided the second input element is set to 0. Since the sigmoid is giving us a probability, and the two probabilities must add to 1, it is not necessary to explicitly calculate a value for the second element.
Softmax Function vs Argmax Function
The softmax function was developed as a smoothed and differentiable alternative to the argmax function. Because of this the softmax function is sometimes more explicitly called the softargmax function. Like the softmax, the argmax function operates on a vector and converts every value to zero except the maximum value, where it returns 1.

It is common to train a machine learning model using the softmax but switch out the softmax layer for an argmax layer when the model is used for inference.
We must use softmax in training because the softmax is differentiable and it allows us to optimize a cost function. However, for inference sometimes we need a model just to output a single predicted value rather than a probability, in which case the argmax is more useful.
When there are multiple maximum values it is common for the argmax to return 1/Nmax, that is a normalized fraction, so that the sum of the output elements remains 1 as with the softmax. An alternative definition is to return 1 for all maximum values, or for the first value only.
Calculating Softmax Function vs Argmax Function
Let us imagine again the input vector [3, 0]. We calculate the softmax as before. The largest value is the first element, so the argmax will return 1 for the first element and 0 for the rest.

It is clear from this example that the softmax behaves like a ‘soft’ approximation to the argmax: it returns non-integer values between 0 and 1 that can be interpreted as probabilities. If we are using a machine learning model for inference, rather than training it, we might want an integer output from the system representing a hard decision that we will take with the model output, such as to treat a tumor, authenticate a user, or assign a document to a topic. The argmax values are easier to work with in this sense and can be used to build a confusion matrix and calculate the precision and recall of a classifier.
Applications of the Softmax Function
Softmax Function in Neural Networks
One use of the softmax function would be at the end of a neural network. Let us consider a convolutional neural network which recognizes if an image is a cat or a dog. Note that an image must be either a cat or a dog, and cannot be both, therefore the two classes are mutually exclusive. Typically, the final fully connected layer of this network would produce values like [-7.98, 2.39] which are not normalized and cannot be interpreted as probabilities. If we add a softmax layer to the network, it is possible to translate the numbers into a probability distribution. This means that the output can be displayed to a user, for example the app is 95% sure that this is a cat. It also means that the output can be fed into other machine learning algorithms without needing to be normalized, since it is guaranteed to lie between 0 and 1.
Note that if the network is classifying images into dogs and cats, and is configured to have only two output classes, then it is forced to categorize every image as either dog or cat, even if it is neither. If we need to allow for this possibility, then we must reconfigure the neural network to have a third output for miscellaneous.
Example Calculation of Softmax in a Neural Network
The softmax is essential when we are training a neural network. Imagine we have a convolutional neural network that is learning to distinguish between cats and dogs. We set cat to be class 1 and dog to be class 2.
Ideally, when we input an image of a cat into our network, the network would output the vector [1, 0]. When we input a dog image, we want an output [0, 1].
The neural network image processing ends at the final fully connected layer. This layer outputs two scores for cat and dog, which are not probabilities. It is usual practice to add a softmax layer to the end of the neural network, which converts the output into a probability distribution. At the start of training, the neural network weights are randomly configured. So the cat image goes through and is converted by the image processing stages to scores [1.2, 0.3]. Passing [1.2, 0.3] into the softmax function we can get the initial probabilities [0.71, 0.29]

Clearly this is not desirable. A perfect network in this case would output [1, 0].

We can formulate a loss function of our network which quantifies how far the network’s output probabilities are from the desired values. The smaller the loss function, the closer the output vector is to the correct class. The commonest loss function in this case is the cross-entropy loss which in this case comes to:
Because the softmax is a continuously differentiable function, it is possible to calculate the derivative of the loss function with respect to every weight in the network, for every image in the training set.
This property allows us to adjust the network’s weights in order to reduce the loss function and make the network output closer to the desired values and improve the network’s accuracy. After several iterations of training, we update the network’s weights. Now when the same cat image is input into the network, the fully connected layer outputs a score vector of [1.9, 0.1]. Putting this through the softmax function again, we obtain output probabilities:

This is clearly a better result and closer to the desired output of [1, 0]. Recalculating the cross-entropy loss,

we see that the loss has reduced, indicating that the neural network has improved.
The method of differentiating the loss function in order to ascertain how to adjust the weights of the network would not have been possible if we had used the argmax function, because it is not differentiable. The property of differentiability makes the softmax function useful for training neural networks.
Softmax Function in Reinforcement Learning
In reinforcement learning, the softmax function is also used when a model needs to decide between taking the action currently known to have the highest probability of a reward, called exploitation, or taking an exploratory step, called exploration.
Example Calculation of Softmax in Reinforcement Learning
Imagine that we are training a reinforcement learning model to play poker against a human. We must configure a temperature τ, which sets how likely the system is to take random exploratory actions. The system has two options at present: to play an Ace or to play a King. From what it has learnt so far, playing an Ace is 80% likely to be the winning strategy in the current situation. Assuming that there are no other possible plays then playing a King is 20% likely to be the winning strategy. We have configured the temperature τ to 2.
The reinforcement learning system uses the softmax function to obtain the probability of playing an Ace and a King respectively. The modified softmax formula used in reinforcement learning is as follows:

Reinforcement Learning Softmax Formula Symbols Explained
| The probability that the model will now take action a at time t. | |
| The action that we are considering taking. For example, to play a King or an Ace. | |
 |
The temperature of the system, configured as a hyperparameter. |
| The current best estimate of the probability of success if we take action i, from what the model has learnt so far. |
Putting our values into the equation we obtain:

This means that although the model is currently 80% sure of the Ace being the correct strategy, it is only 57% likely to play that card. This is because in reinforcement learning we assign a value to exploration (testing out new strategies) as well as exploitation (using known strategies). If we choose to increase the temperature, the model becomes more ‘impulsive’: it is more likely to take exploratory steps rather than always playing the winning strategy.
Softmax History
The first known use of the softmax function predates machine learning. The softmax function is in fact borrowed from physics and statistical mechanics, where it is known as the Boltzmann distribution or the Gibbs distribution. It was formulated by the Austrian physicist and philosopher Ludwig Boltzmann in 1868.
Boltzmann was studying the statistical mechanics of gases in thermal equilibrium. He found that the Boltzmann distribution could describe the probability of finding a system in a certain state, given that state’s energy, and the temperature of the system. His version of the formula was similar to that used in reinforcement learning. Indeed, the parameter τ is called temperature in the field of reinforcement learning as a homage to Boltzmann.
In 1902 the American physicist and chemist Josiah Willard Gibbs popularized the Boltzmann distribution when he used it to lay the foundation for thermodynamics and his definition of entropy. It also forms the basis of spectroscopy, that is the analysis of materials by looking at the light that they absorb and reflect.
In 1959 Robert Duncan Luce proposed the use of the softmax function for reinforcement learning in his book Individual Choice Behavior: A Theoretical Analysis. Finally in 1989 John S. Bridle suggested that the argmax in feedforward neural networks should be replaced by softmax because it “preserves the rank order of its input values, and is a differentiable generalisation of the ‘winner-take-all’ operation of picking the maximum value”. In recent years, as neural networks have become widely used, the softmax has become well known thanks to these properties.