What are Naive Bayes Classifiers?
Naive Bayes classifiers are a set of probabilistic classifiers that aim to process, analyze, and categorize data. Introduced in the 1960's Bayes classifiers have been a popular tool for text categorization, which is the sorting of data based upon the textual content. An example of this is email filtering, where emails containing specific suspicious words may be flagged as spam.
How do Naive Bayes Classifiers work?
Naive Bayes is essentially a technique for assigning classifiers to a finite set. However, there is no single algorithm for training these classifiers, so Naive Bayes assumes that the value of a specific feature is independent from the value of any other feature, given the class variable. For example, a machine may be considered to be a car because it is large, has four wheels, and a rectangular shape. The Naive Bayes classifier would consider each of these features to contribute independently to the likelihood that the object is a car, regardless of any correlations between number of wheels, size, or shape.

Image from Wikipedia.com
The formula above represents the Bayes rule. However, in the context of classification, A becomes c_i, and B becomes our features x_0 through x_n. Because the Naive Bayes classifiers assume the values of each feature are independent from each other, the formula can assume that:
P(x_0, …, x_n | c_i) = P(x_0 | c_i) * P(x_1 | c_i) * … * P(x_n | c_i).
Therefore, our final representation is as follows:
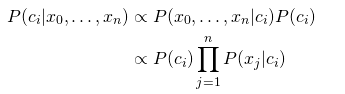
Image from Wikipedia.com
Naive Bayes classifiers will use this model to classify data based upon the c_i that has the largest probability given the data point's features. This is also known as the Maximum A Posteriori decision rule.
Naive Bayes Classifiers and Machine Learning
Used almost exclusively in data science, the Naive Bayes classifiers provide a simple, yet effective way to train a neural network to classify and identify data. Sometimes represented simply as a bayesian network, the classifiers are frequently used toward applications of text classification, providing solutions for problems such as spam detection.